4. Gaming AGI
Our Gaming AGI starts with a model framework that deeply integrates multimodal large language models ("MLLMs") with a Reinforcement Learning Model Library ("RLML"), both enhanced for gaming-specific tasks. This approach produces immersive, dynamic, and sophisticated AI game experiences through AI agents or game worlds.
Overview
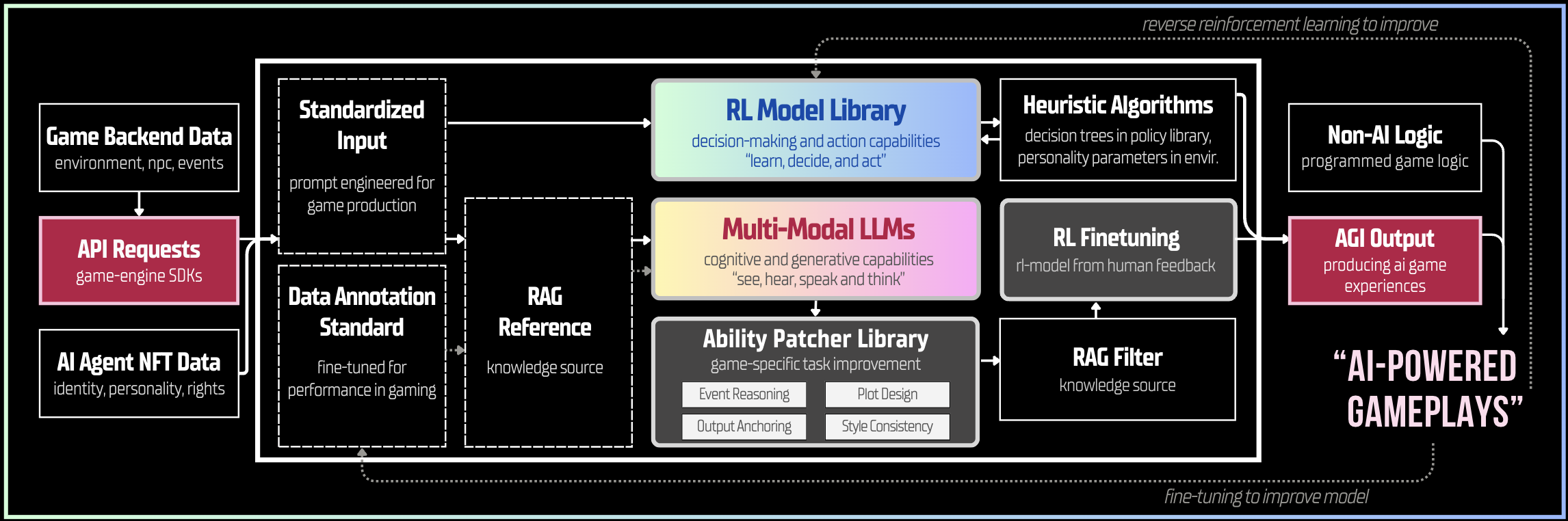
1. Framework Design
Our framework consolidates the abilities for agents to see, hear, speak, think, learn, decide, and act into a unified general intelligence that understands and reacts to dynamic game contexts.
MLLMs equip our Gaming AGI with cognitive and generative capabilities. The former enables our Gaming AGI to see, hear, and think for contextual understanding of gameplays. The latter enables it to respond in data types, including text, audio, image, and foreseeably, video, 3D object, and action animation.
RLML equips our Gaming AGI with decision-making and action capabilities. It enables our Gaming AGI to optimize state-to-state decisions and react to dynamic gaming contexts for diversified purposes. Our Gaming AGI continues to "learn" capabilities as our RL Library expands.
The integration focuses on layering action-based learning atop cognitive functions. The contextual knowledge from MLLMs can inform RL decision-making processes, reducing the sample inefficiency and allowing them to interpret complex inputs, and reason about the world in human-like ways.
Moving forward, the integration shifts towards fully grounding MLLMs within RL frameworks. This process of grounding perception in decisions and actions creates a unified intelligence that processes complex scenarios and actions within one system. This is when the Gaming AGI Framework transforms into a real Gaming AGI. Our team's research on multimodality and LLM grounding is in the Publication & Patent section.
2. Current Components
The components are designed to enhance gaming-specific task performance.
Prompt Engineering & Prompt Learning enables our Gaming AGI to understand standardized input for specific outcomes, improving integrability and output control for game developers.
Multimodal Parameter-Efficient Fine-Tuning enables fine-tuning a small number of model parameters, enhancing the cost-efficiency and the performance of gaming-related tasks.
Ability Patchers enhances game-specific capabilities and performance, such as event reasoning, dynamic soundscaping, voice cloning, for more immersive and dynamic game experiences.
RAG grounds MLLMs on external sources of knowledge for changing requirements or cross-functional usage, ameliorating problems such as hallucination.
Reinforcement Learning from Human Feedback ("RLHF") empowers the system to learn from player feedback and iteratively improve based on real-time evaluations and preferences.
Transfer Learning of RL transfers knowledge from trained RL agents to untrained agents in similar but not identical settings. This helps us achieve higher versatility of our RL models.
R&D Guiding Principles
Our R&D focuses on developing modular, gaming-specific technologies that is irreplaceable amid the rapid development of AI technologies. The MLLM backbone, the field-specific knowledge base for RAG, the different designs of ability patchers, and many other components are all connected yet relatively isolated, which allows us to always position ourselves at the forefront of AI technologies.
Propositions
Large training datasets are required.
Fine-tuning for task-specific improvements requires large and well-labeled training datasets—hundreds or thousands of hours for scrubbing and labelling.
1/ AI Game Hub as an organic community to foster data that are accurate, comprehensive, reliable, relevant, and timely for gaming. 2/ Multimodal Parameter-Efficient Fine-Tuning for task-specific fine-tuning efficiency.
Massive compute resources are required. Foundation models (e.g. LLMs) are trained on a vast array of unlabeled data for high task adaptability with minimal fine-tuning. These models expand in size to assimilate, leading to highly costly fine-tuning.
1/ Our Compute Network facilitates access to reliable and affordable compute resources. 2/ Multimodal Parameter-Efficient Fine-Tuning enables efficient adaptation of large models by fine-tuning only a small number of (extra) model parameters
Limited accessibility and usability of AI. AI models lack uniform standards, which complicate their integrations into game production workflows. RL models require unique sets of environment setups while LLM interactions are prompt-based.
1/ Prompt engineering & prompt learning enables our ability SDKs to take standardized and game-compatible input for Gaming AGI output trained for game contexts. 2/ End-to-end solutions designed for game experiences powered by both MLLM and RL.
Current AI does not meet developer needs. Prevailing AI models are mostly general-purposed and are limited in game tasks such as limited: memory, reasoning, output resolution, action capability, 3D generation capability, and animation productivity.
1/ Ability patchers adopts SOTA concepts to tackle common limitations, such as embedding task-specific models into the MLLMs. 2/ RAG ameliorates problems such as memory.
3/ Integrated framework that enables it to see, hear, speak, think, learn, decide, and act.
AI hallucination—AI models detect patterns or objects not perceivable by human observers. This may result in nonsensical, irrelevant, or inaccurate outputs that disrupt game immersiveness.
1/ RAG ensures context and worldview appropriateness by grounds models on external sources of knowledge.
Lack of adaptability of RL agents. to settings out of the training environments. The close coupling means that AI actions are hardly versatile to new games.