Architecture
Task Process
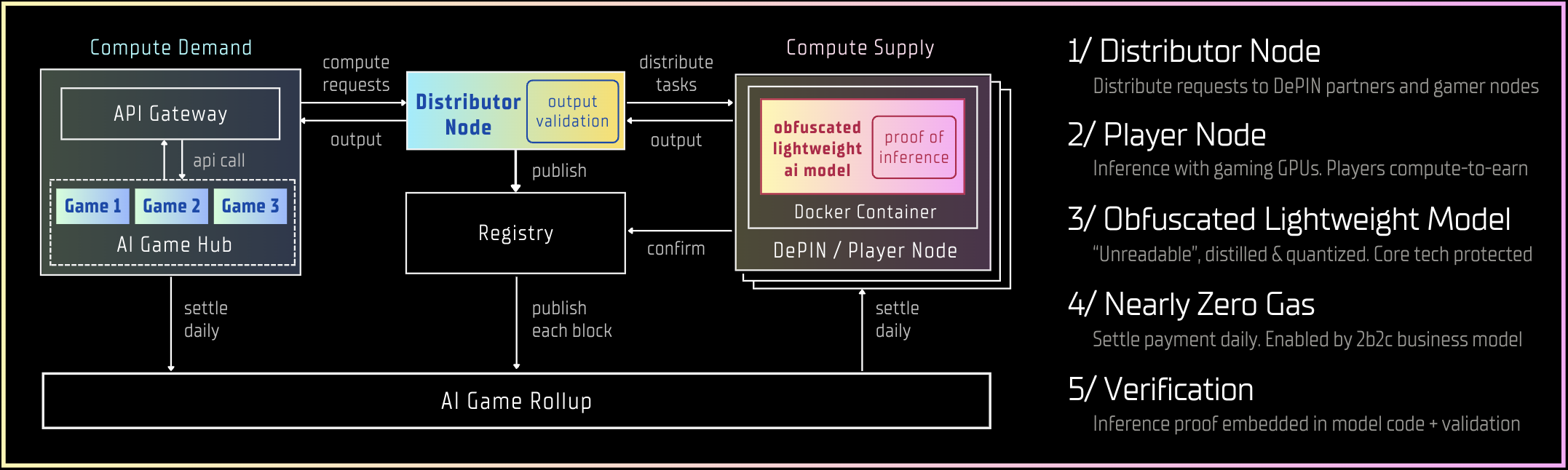
To streamline AI inferencing for game developers and ensure a low-latency experience for AI players, the Compute Network workflow involves several key steps:
API Gateway: We offer comprehensive SDKs for games within our Game Hub. When a game initiates an inferencing request, the API Gateway forwards the request to the Distributor Node.
Task Assignment: The Distributor Node encrypts the prompt in each request to maintain confidentiality. It then assigns the task to the most suitable compute node ("Node") from our DePIN partners or players, considering factors such as current workload and response time.
Model Execution: The Node runs our obfuscated lightweight models based on the prompt and reverts the resulting output to the Distributor Node. In addition, the Node has to confirm its completed tasks with the Registry every block.
Output Verification: Upon receiving the output from the Node, the Distributor Node verifies the proof of inference and relays the decrypted output back to the game. It then updates the Registry about the task's completion.
Transaction Completion: Following confirmations from the Node, the Registry posts the record onto the Gaming AGI Rollup ("Rollup") every block. For a designated number of blocks (roughly 24 hours), the transaction cost of the day is settled among AI game developers and compute suppliers.
Component Highlights
There are three key components in the architecture, each with specific responsibilities:
Distributor Node: The Distributor Node is crucial in managing AI inferencing requests within our Compute Network, serving as the intermediary between the AI Game Hub and compute suppliers. Its main tasks include encrypting and decrypting inferencing requests, distributing tasks based on Player Node performance, verifying the proof of inference, and conducting random output quality checks to ensure the reliability and accuracy of the outputs.
Compute Supplier: Nodes from DePIN partners and player nodes can integrate into the Compute Network as Player Nodes by downloading our Docker Container. This container is designed for easy installation across various operating systems, facilitating a straightforward connection to our Compute Network for AI inferencing tasks and earning tokens.
Registry: The Registry acts as a temporary ledger, documenting daily transactions between the Distributor Node and Player Nodes. At the close of each day, the Registry compiles these transactions into our Rollup, which then processes token settlements with Player Nodes.
Value Propositions
Our Compute Network is designed to effectively address GPU memory limitations, security concerns, and cost-efficiency challenges encountered in traditional DePIN systems. Key highlights of our Compute Network include:
AI Model Protection: We employ advanced model obfuscation technology to ensure that AI models are safeguarded against theft and unauthorized access, protecting the core technology.
Inferencing Safety: To ensure the inferencing output is generated by our AI models, a proof of inference module is deeply integrated into the inferencing process. As the Node runs the model, the SDK generates a sequence of secret codes that are verified by the Distributor Node when the output is sent back to the AI Game.
Lightweight AI Models: Through the use of distillation and quantization techniques, we significantly reduces the size of large language models, making it possible to run these models on personal gaming computers with as little as 8GB of GPU memory.
Minimal Gas Fees: The unique structure of our AI gaming ecosystem ensures that the AI Game Rollup does not need to settle each transaction immediately after task completion. This approach is viable because all AI game developers are considered trustworthy entities. Failure to cover inferencing costs results in severe penalties, including the potential removal of their games from the AI Game Hub. Therefore, the Registry can publish transactions to the AI Game Rollup only once daily, keeping gas fees negligible.
Last updated